This is a PSA for folks with an audio corpus of a low resource language: it is getting possible to build a decent speech recognition system with remarkably little transcribed data. Take this into account next time you are discussing acceptable use of new recordings, and double check how community members feel about these possibilities.
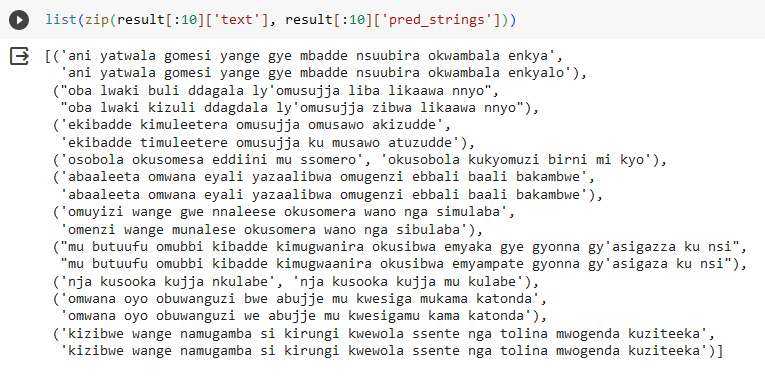
Over the past couple weekends I participated in an effort to “finetune” speech recognition models for each of the ~60 languages in the Common Voice dataset. I focused on Luganda because the languages I know more about either are not in the dataset or were well-covered by other participants. Using about 6 hours of read speech for training (i.e. people read sentences from public domain documents, and no separate text data was used for a language model), the resulting model reaches 23% word-error-rate, and considering that Bantu words are relatively long, this means it’s potentially useful for jump-starting transcription work, indexing an untranscribed audio corpus, or enabling a voice interface. It’s likely that an even lower error rate is possible using audio data from a related language for initial training, or using text data to guide the output.